Это черновик для будущей заметки в блог "Парсинг сайтов в элементы инфоблока".
Покажу на простом примере, в заметке будет расширенный вариант с парсингом товаров каталога.
У нас есть некая страница, с такой HTML структурой:
Нам нужно спарсить к себе на сайт при этом каждая строка должна заполниться в свойства инфоблока с соответствующим содержимым.
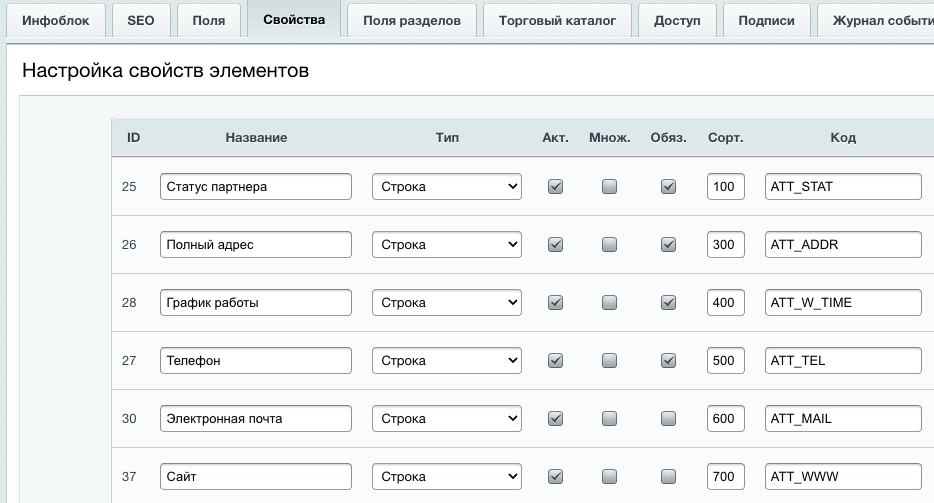
Для этого нам нужны коды или ID заведомо созданных свойств инфоблока.
Используем следующий скрипт для парсинга:
Покажу на простом примере, в заметке будет расширенный вариант с парсингом товаров каталога.
У нас есть некая страница, с такой HTML структурой:
| Код |
|---|
<div class="it"> <h4 class="ti">Сайдинг-Россия</h4> <div class="con"> Официальный дистрибьютор<br> 140300, Московская область, г. Егорьевск, ул. Рязанская, д.107с1<br> телефон: +7 (966) 000-36-36<br> график работы: ежедневно 9:00—18:00<br> email: siding-russia@mail.ru<br> https://siding-russia.ru/ </div> </div> <div class="it"> <h4 class="ti">Виниловая торговая компания</h4> <div class="con"> Официальный дистрибьютор<br> 141212, Московская область, Пушкинский городской округ, село Тарасовка, ул. Центральная, вл.52, стр. 2<br> телефон: +7 (495) 799-45-67<br> график работы: пн — вс 09:00 — 18:00<br> email: sale2@vtcopt.ru<br> https://vtcopt.ru/ </div> </div> И так далее любое количество таких блоков |
Нам нужно спарсить к себе на сайт при этом каждая строка должна заполниться в свойства инфоблока с соответствующим содержимым.
Для этого нам нужны коды или ID заведомо созданных свойств инфоблока.
Используем следующий скрипт для парсинга:
| Код |
|---|
<?php
// Подключение ядра битрикса
require_once($_SERVER["DOCUMENT_ROOT"] . "/bitrix/modules/main/include/prolog_before.php");
// Указываем URL страницы, которую нужно скачать и распарсить
$url = 'http/пример-сайта.ru/1.php'; // Замените на нужный сайт и путь
// Загружаем HTML страницы через cURL (можно и через file_get_contents, если настройки позволяют)
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// Если нужно, можно добавить настройки авторизации, прокси, юзер-агент и т.п.
$html = curl_exec($ch);
curl_close($ch);
// Проверка успешной загрузки
if (!$html) {
die("Ошибка загрузки страницы");
}
// Создаем DOMDocument и загружаем HTML
$dom = new DOMDocument();
libxml_use_internal_errors(true); // Отключаем ошибки парсера из-за некорректного HTML
$dom->loadHTML($html);
libxml_clear_errors();
// Используем XPath для поиска нужных элементов
$xpath = new DOMXPath($dom);
// Ищем все блоки с классом 'it'
$blocks = $xpath->query("//*[contains(@class, 'it')]");
$result = []; // Массив для хранения данных
foreach ($blocks as $block) {
// В каждом блоке ищем заголовок h4 с классом 'ti'
$titleNode = $xpath->query(".//h4[@class='ti']", $block)->item(0);
$title = $titleNode ? trim($titleNode->nodeValue) : '';
// Внутри блока ищем div с классом 'con'
$conNode = $xpath->query(".//div[@class='con']", $block)->item(0);
if ($conNode) {
// Получаем HTML содержимого div, чтобы разбивать по <br>
$conHTML = $dom->saveHTML($conNode);
// Разбиваем по тегам <br> (учитываем оба варианта: <br> и <br/>)
$lines = preg_split('/<br\s*\/?>/i', $conHTML);
// Очистка каждой линии от тегов и пробелов
$linesClean = array_map(function($line) {
return trim(strip_tags($line));
}, $lines);
// Добавляем данные в массив
$result[] = [
'TITLE' => $title,
'CONTENT_LINES' => $linesClean,
];
}
}
// Обработка результатов: добавляем в инфоблок
// Подключаем модуль инфоблоков
CModule::IncludeModule("iblock");
// Создаем объект для добавления элементов
$el = new CIBlockElement;
// Идентификатор инфоблока, куда добавляем
$IBLOCK_ID = 4; // Замените на ваш ID инфоблока
foreach ($result as $item) {
// Тут можно просматривать данные перед добавлением
//echo '<pre>';
//print_r($item);
//echo '</pre>';
// Формируем свойства для элемента
$PROP = array();
// Предполагая, что у вас есть определенные свойства по номерам:
// Пример адаптируйте под свои свойства:
if (isset($item['CONTENT_LINES'][0]))
$PROP[25] = trim($item['CONTENT_LINES'][0]); // например, адрес
if (isset($item['CONTENT_LINES'][1]))
$PROP[29] = trim($item['CONTENT_LINES'][1]); // телефон
if (isset($item['CONTENT_LINES'][2]))
$PROP[26] = trim($item['CONTENT_LINES'][2]); // И так далее
if (isset($item['CONTENT_LINES'][3]))
$PROP[28] = trim($item['CONTENT_LINES'][3]);
if (isset($item['CONTENT_LINES'][4]))
$PROP[27] = trim($item['CONTENT_LINES'][4]);
if (isset($item['CONTENT_LINES'][5]))
$PROP[30] = trim($item['CONTENT_LINES'][5]);
if (isset($item['CONTENT_LINES'][6]))
$PROP[37] = trim($item['CONTENT_LINES'][6]);
// Создаем массив данных для нового элемента
$fields = [
'IBLOCK_ID' => $IBLOCK_ID,
'NAME' => $item['TITLE'], // название элемента
'PROPERTY_VALUES' => $PROP,
'ACTIVE' => 'Y',
// Можно добавить 'PREVIEW_TEXT' или 'DETAIL_TEXT', если нужно
//'PREVIEW_TEXT' => implode("\n", $item['CONTENT_LINES']),
];
// Добавляем элемент инфоблока
$elementId = $el->Add($fields);
if (!$elementId) {
echo 'Ошибка добавления элемента: ', $el->LAST_ERROR, "<br>";
} else {
echo "Добавлен элемент ID: ", $elementId, "<br>";
}
}
// Подключаем завершающую часть битрикса
require_once($_SERVER['DOCUMENT_ROOT'] . '/bitrix/modules/main/include/epilog_after.php');
?> |